

AWS ha publicado el post-mortem de la gran incidencia del 19–20 de octubre que afectó a la región N. Virginia (us-east-1). La raíz del problema: un fallo de carrera en la automatización interna que gestiona el DNS de DynamoDB. El sistema acabó aplicando un plan vacío para el endpoint regional y dejó de resolver dynamodb.us-east-1.amazonaws.com. Desde ahí, el efecto dominó fue inmediato: IAM, STS, EC2, Lambda, NLB, ECS/EKS/Fargate, Redshift y otros servicios que dependen directa o indirectamente de DynamoDB empezaron a fallar en cadena.
AWS detuvo esa automatización a nivel mundial, restauró manualmente el estado correcto de DNS para DynamoDB y, con reinicios y desatascos selectivos, fue recuperando la región de forma gradual.
Qué pasó (cronología resumida, hora de Madrid)
- Lun 20/10, 08:48–11:40 CEST. Aumento de errores en APIs de DynamoDB en us-east-1 por fallo de resolución DNS del endpoint regional. Tráfico de clientes y servicios internos de AWS no podía abrir conexiones nuevas. La restauración de DNS y la expiración de cachés devolvieron la conectividad hacia las 11:40.
- 10:25–19:36 CEST. Lanzar nuevas instancias EC2 empezó a fallar (las existentes siguieron sanas). Tras arreglar DynamoDB, el gestor de flota física (DWFM) entró en colapso congestivo al intentar re-establecer millones de “arrendamientos” con servidores físico-huésped; hicieron reinicios selectivos y throttling hasta normalizar a las 19:50.
- 14:30–23:09 CEST. Network Load Balancer (NLB) vio picos de errores de conexión por flapping en sus health checks: incorporaba nodos cuyo estado de red aún no se había propagado, marcándolos como malos y activando failovers de AZ. AWS desactivó esa conmutación automática y luego la reactivó al final de la recuperación.
En paralelo, Lambda limitó invocaciones, ECS/EKS/Fargate sufrieron fallos de arranque y Connect, STS o Redshift encadenaron impactos al depender de endpoints o lanzamientos nuevos en EC2.
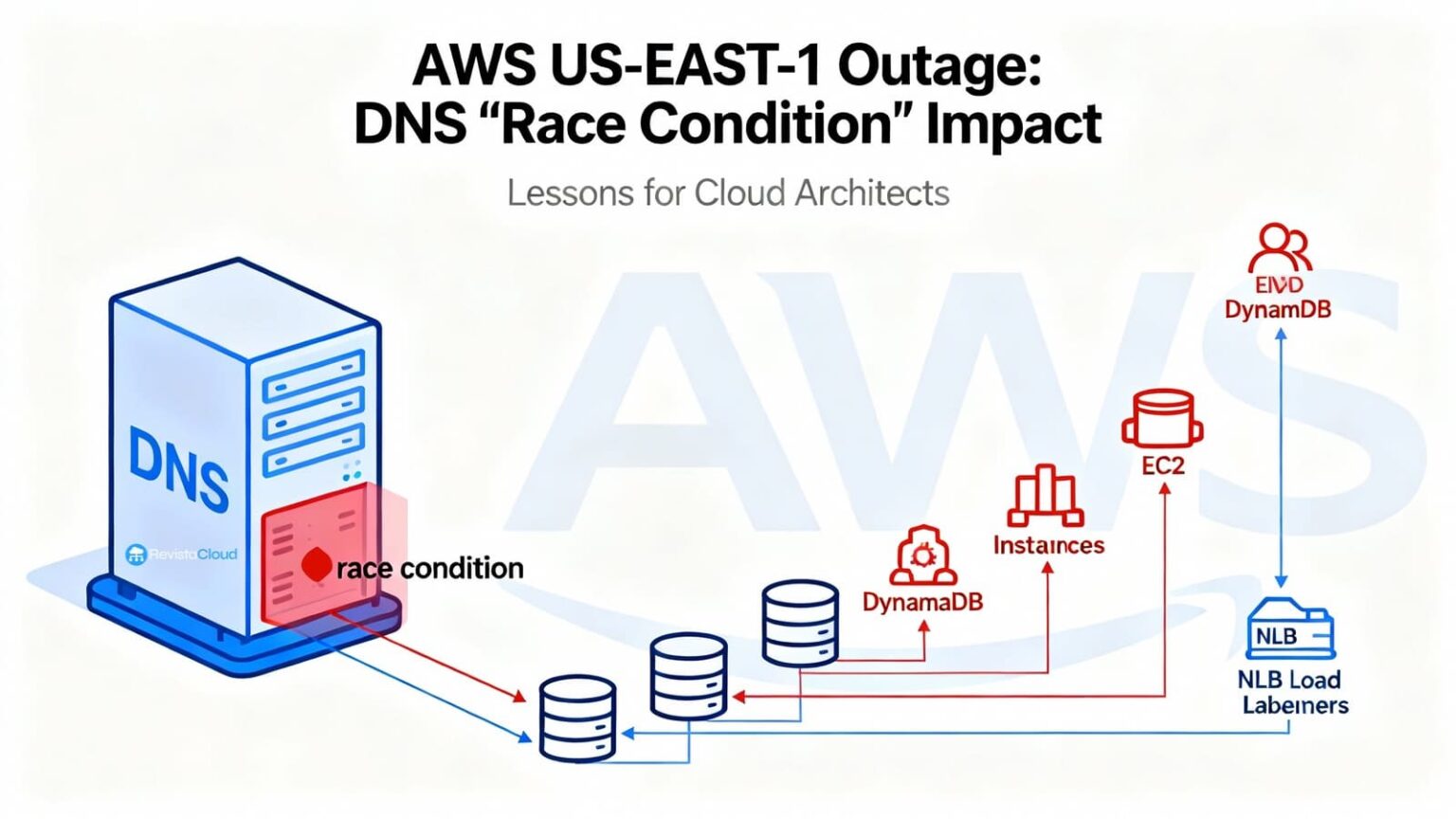
La raíz: cómo un “race condition” en el DNS de DynamoDB vació el endpoint
DynamoDB opera cientos de miles de registros DNS por región para balancear un parque heterogéneo de load balancers y variantes (FIPS, IPv6, endpoints por cuenta). Para ello mantiene dos piezas:
- DNS Planner: calcula planes DNS (LBs + pesos) por endpoint.
- DNS Enactor: aplica esos planes en Route 53 mediante transacciones; hay tres Enactors, uno por AZ, trabajando en paralelo para resiliencia.
El incidente se produjo cuando un Enactor muy retrasado terminó aplicando un plan antiguo justo a la vez que otro Enactor acababa de aplicar un plan nuevo y lanzaba su limpieza de planes viejos. La ventana temporal hizo que el plan viejo machacara el nuevo en el endpoint regional y, acto seguido, la limpieza borrara ese plan por obsoleto, dejando el endpoint sin IPs. Además, el sistema quedó en un estado inconsistente que impedía a los Enactors posteriores reparar la situación. Fue necesaria intervención manual para restaurar los registros correctos y desbloquear la automatización.
Por qué se cayó “todo” a la vez: dependencias cruzadas
- Control plane vs. data plane. Muchos subsistemas de AWS gestionan estado (leases, catálogos, colas internas) en DynamoDB. Con el endpoint caído, el control plane de servicios críticos se quedó sin “base de datos de coordinación”.
- Propagación de red diferida. Tras restablecer EC2, Network Manager arrastraba una cola masiva de propagaciones de estado de red para nuevas instancias, lo que dejó lanzamientos “ciegos” (sin conectividad) hasta vaciar el backlog. Eso, a su vez, engañó a los health checks de NLB.
Qué cambia a partir de ahora (según AWS)
- Automatización DNS de DynamoDB (Planner/Enactor) deshabilitada globalmente hasta corregir el escenario de carrera y añadir protecciones para impedir planes incorrectos.
- NLB: control de velocidad para limitar cuánta capacidad puede retirar un solo NLB ante fallos de health check y evitar failovers agresivos.
- EC2: nueva batería de tests para el flujo de recuperación de DWFM y mejoras de throttling basadas en tamaño de colas.
Lecciones para equipos de plataforma (y SRE) que operan en AWS
1) Diseña para perder una región… y una dependencia interna.
- Activa-activa multi-región para planos de datos que lo permitan (p. ej., DynamoDB Global Tables), con mecanismos de conmutación y lag asumible.
- Ten un plan B si el control plane no responde (no hay lanzamientos nuevos, ni escalado, ni credenciales de corta vida renovadas). Piensa en capacidad “caliente” pre-provisionada para pasar el bache.
2) DNS: cachea de forma sensata y evita “TTL 0” por defecto.
- La caché DNS amortigua fallos transitorios de resolución. Ajusta resolvers y TTL para endpoints críticos, pero no fijes IPs de servicios gestionados.
3) Health checks con cabeza (y sin flapping).
- No hagas failover en cascada por health checks inconsistentes. Aumenta intervalos, thresholds y usa grace periods cuando hay despliegues masivos o propagaciones de red pendientes. La lección de NLB va en esa línea.
4) Circuit breakers y degradación funcional.
- Que la aplicación sepa operar “degradada” si no puede crear recursos nuevos (p. ej., colas locales temporales, lectura-solo, features no esenciales desactivadas).
5) Credenciales y STS.
- Evita caducidades sincronizadas; escalona la rotación de tokens y da margen si STS/IAM se ve afectado en una región.
6) Runbooks y simulacros.
- Documenta “cuando us-east-1 está roto”: rutas de emergencia, listas de allow/deny temporales, throttling para no colapsar tus propios workers al volver el plano de control.
Opinión: ¿es us-east-1 el “canario” de AWS?
Históricamente, buena parte de los Post-Event Summaries más sonados han ocurrido en us-east-1 —también es, con diferencia, la región más grande y antigua de AWS—, lo que la convierte en punto de máxima complejidad y, sí, de mayor exposición a eventos con efecto sistémico. La lección no es “huir” de Virginia, sino no depender en exclusiva de ella para control plane y datos críticos.
Qué deben comunicar los equipos ahora mismo
- Estado: qué servicios propios se vieron afectados (lanzamientos, colas, pagos, login), cuándo y cómo se mitigó.
- Riesgos residuales: si queda deuda operativa (p. ej., batches re-procesándose).
- Plan: próximos cambios (multi-región, caché DNS, health checks, límites de ráfagas, capacidad pre-asignada) y fechas.
Checklist práctico de mitigación (resumen)
- Multi-AZ + multi-región para workloads críticos; simular pérdida de endpoint regional.
- TTL DNS razonables para servicios gestionados; resolver local robusto.
- Backoff/jitter agresivo en clientes, y circuit breakers.
- Throttle controlado al volver (evita “congestive collapse”).
- Health checks menos sensibles en picos de despliegue; evitar flapping.
- STS/IAM con expiraciones escalonadas y margen.
- Runbooks con contacto on-call y métricas de “listo para conmutar”.
Fuentes
Post-mortem y medidas anunciadas por AWS (automatización DNS de DynamoDB deshabilitada, cambios en NLB y EC2), más cobertura técnica independiente sobre la secuencia del evento y el impacto por servicios.
















{kind=link}