

La forma de descubrir y consumir información en Internet está cambiando de manera silenciosa pero profunda. Ya no se trata solo de aparecer en buscadores: cada vez más contenidos llegan a los usuarios filtrados por asistentes, resúmenes automáticos y agentes de Inteligencia Artificial que “leen” páginas para responder preguntas, comparar opciones o ejecutar tareas. En ese nuevo tablero, empieza a ganar peso una pregunta incómoda para cualquier editor, marca o negocio: ¿está mi web preparada para ser interpretada por máquinas sin perder contexto, matices o datos clave?
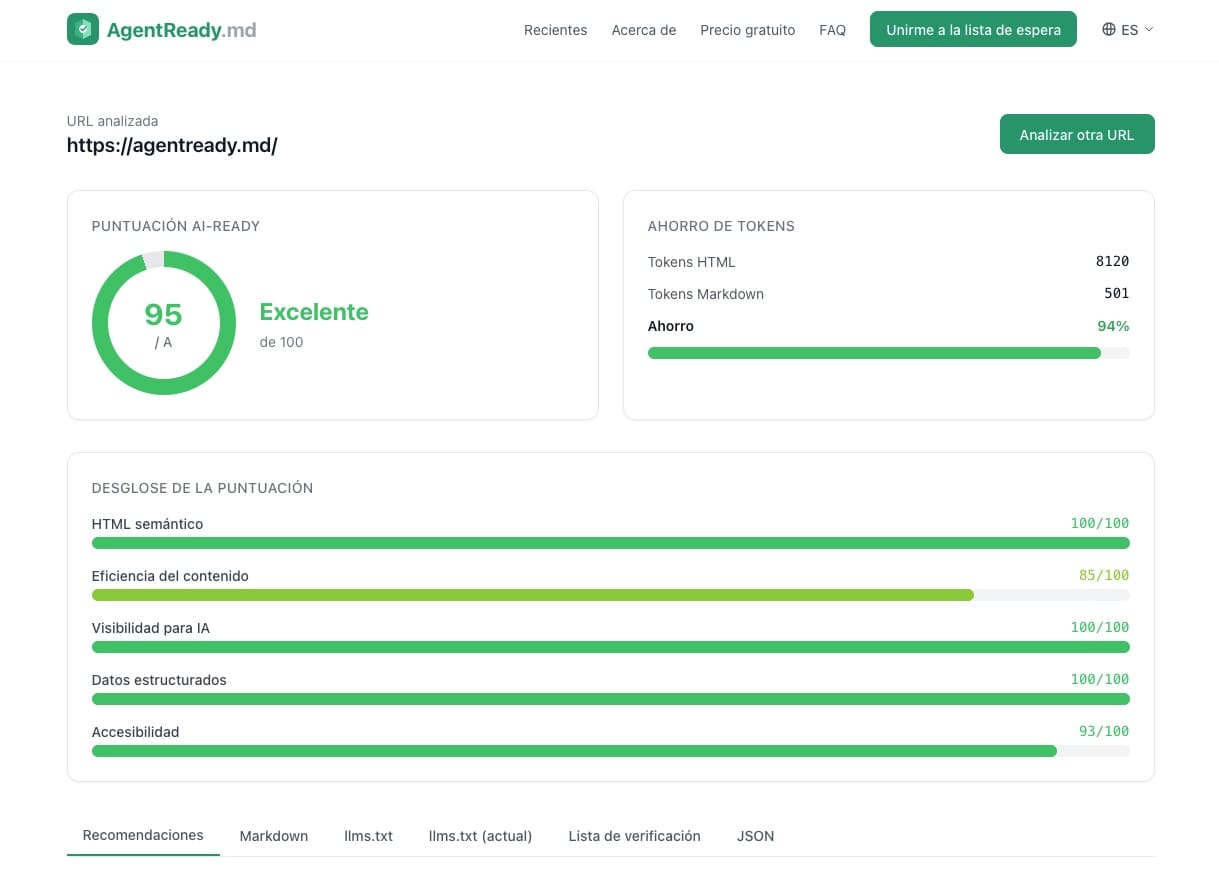
Con esa premisa aterriza AgentReady.md, una herramienta online gratuita que analiza una URL y devuelve, en segundos, una puntuación de “AI-readiness” acompañada de recomendaciones priorizadas, una conversión a Markdown y una guía paso a paso con fragmentos listos para implementar. Funciona sin registro y, en fase beta, limita el uso a un máximo de 5 análisis por hora, un detalle que apunta a su vocación de herramienta práctica más que de auditoría masiva para grandes cuentas.
De “posicionarse” a “ser legible”: el cambio de mentalidad
Durante años, el SEO se centró en ayudar a los motores de búsqueda a entender una página: títulos, estructura, enlaces internos, datos estructurados. Los agentes de IA, sin embargo, consumen la web con otras prioridades. No “navegan” como una persona: tienden a extraer el contenido principal, reducir ruido, interpretar secciones y decidir qué es relevante para una tarea concreta.
Ahí aparece el concepto de eficiencia del contenido: no solo importa qué dice una página, sino cuánto “relleno técnico” hay que atravesar para llegar a lo importante. En términos de modelos de lenguaje, ese relleno suele traducirse en tokens (el “presupuesto” de texto que una IA puede procesar), con impacto directo en coste, latencia y calidad del resultado. La propia AgentReady.md sostiene que una página bien estructurada, al convertirse a Markdown, puede requerir entre un 70 % y un 80 % menos de tokens que el HTML en bruto.
Un análisis pensado para convertirse en tareas concretas
La propuesta de AgentReady.md se apoya en un flujo muy simple:
- Se introduce una URL: el sistema obtiene la página y analiza su estructura.
- Devuelve una puntuación: la nota se calcula a partir de 5 dimensiones y 21 comprobaciones.
- Prioriza mejoras: el informe se traduce en acciones con snippets de “copiar y pegar”.
La clave está en que el resultado no se queda en un diagnóstico genérico del tipo “mejora tu accesibilidad”, sino que intenta bajar al barro: qué falta, dónde y qué se recomienda tocar primero para subir nota.
Las 5 dimensiones: dónde tropiezan muchas webs sin saberlo
La herramienta divide el “AI-readiness” en cinco bloques que, vistos en conjunto, dibujan el mapa de riesgos más habitual:
- HTML semántico: uso correcto de
article,main, encabezados coherentes, elementos semánticos y textos alternativos de imágenes. - Eficiencia del contenido: ratio de reducción de tokens, proporción contenido/ruido, estilos en línea y “peso” general de la página.
- Descubribilidad para IA: presencia de
llms.txt,robots.txt, permisos a bots,sitemap, negociación de Markdown y cabeceras tipo Content-Signal. - Datos estructurados: Schema.org/JSON-LD, Open Graph, meta description, canonical y atributo de idioma.
- Accesibilidad: disponibilidad de contenido sin depender de JavaScript, tamaño de página y posición del contenido en el HTML.
Traducido a lenguaje llano: AgentReady.md intenta medir si una web tiene estructura, señales y limpieza suficiente como para que un consumidor no humano entienda rápido qué es cada cosa, encuentre lo importante y no se pierda en menús, bloques repetidos o plantillas infladas.
Por qué llms.txt suena cada vez más en marketing y contenidos
Uno de los elementos que más interés despierta es llms.txt, un estándar emergente que busca hacer para los agentes lo que robots.txt hizo para los buscadores: una guía clara, en Markdown, con un “mapa” de páginas clave. La propia herramienta distingue entre:
- llms.txt: índice conciso con enlaces y descripciones.
- llms-full.txt: versión extendida con contenido incluido “en línea” para evitar saltos entre URLs.
Para un medio, un ecommerce o una empresa de servicios, esto abre un nuevo terreno: curar qué páginas son “núcleo”, cómo se describen y en qué orden se ofrecen a un lector automático. En la práctica, es una capa editorial adicional: no cambia el contenido, pero sí la forma en la que se entrega y se descubre.
El contexto: Cloudflare también empuja el giro hacia Markdown
El debate no aparece en el vacío. Cloudflare ha presentado “Markdown for Agents”, un enfoque basado en negociación de contenido: cuando un agente pide una página con la cabecera Accept: text/markdown, la red convierte el HTML a Markdown en el edge y devuelve un resultado más limpio. La compañía ejemplifica el impacto con una cifra llamativa: una misma página puede pasar de 16.180 tokens en HTML a 3.150 en Markdown, cerca de un 80 % menos.
El mensaje de fondo es claro: si los agentes serán una parte creciente del “tráfico” futuro, la industria está empezando a tratar el formato de entrega como un factor estratégico. Y eso conecta directamente con la utilidad de AgentReady.md: medir hoy, con una URL concreta, qué barreras impiden esa lectura eficiente.
Tabla rápida: HTML vs Markdown visto por un lector automático
| Aspecto | HTML tradicional | Markdown optimizado |
|---|---|---|
| Ruido (clases, contenedores, scripts) | Alto | Bajo |
| Estructura (títulos, listas, secciones) | Puede quedar enterrada | Más explícita |
| Coste en tokens para IA | Mayor | Menor |
| Riesgo de “perder” contenido al extraer | Medio/alto (según heurísticas) | Medio (depende de la conversión) |
| Control editorial sobre lo que se entrega | Normalmente indirecto | Más directo (si se publica/negocia bien) |
Una advertencia útil: no existe el atajo mágico
Herramientas como AgentReady.md ayudan a convertir una conversación difusa (“mi web está lista para IA”) en tareas medibles. Pero no eliminan el núcleo del problema: si el HTML es caótico, si el contenido principal está enterrado o si todo depende de JavaScript para mostrarse, cualquier extractor —humano o máquina— lo tendrá más difícil.
La oportunidad, en cambio, es tangible: ordenar estructura, limpiar ruido, reforzar metadatos y publicar señales claras puede ser un trabajo incremental con impacto acumulativo. Y, para muchos proyectos, es más realista que rehacer un sitio desde cero solo por la llegada de los agentes.
Preguntas frecuentes
¿AgentReady.md sirve solo para medios y blogs, o también para negocios locales y ecommerce?
Funciona especialmente bien en webs donde la comprensión automática importa: contenidos informativos, fichas de producto, páginas de servicios y documentación. En todos esos casos, estructura y metadatos influyen en cómo un agente resume o cita.
¿Qué cambios suelen mejorar más rápido la puntuación de “AI-readiness”?
Normalmente, corregir la jerarquía de encabezados, añadir textos alternativos en imágenes relevantes, reforzar metadatos básicos (idioma, canonical, descripción) y reducir bloques repetidos de navegación o plantillas.
¿Qué es llms.txt y por qué se está comparando con robots.txt?
Es un archivo en Markdown que actúa como guía para agentes: describe el sitio y apunta a páginas clave. No reemplaza robots.txt, pero puede facilitar que un consumidor no humano encuentre “lo importante” sin recorrer todo el dominio a ciegas.
¿Servir Markdown a agentes puede afectar al SEO tradicional?
Si se hace mediante negociación de contenido manteniendo una única URL canónica, la idea es complementar, no duplicar. El objetivo es que humanos reciban HTML y agentes reciban un formato más eficiente, sin crear “páginas espejo”.
Fuente: AgentReady en Redes Sociales
















{kind=link}